2021-09-28
Da in der ursprünglichen Dokumentation Zisternenmessungen der Abschnitt "Änderungsprotokoll, Analysen und Vorhaben" zu umfangreich und zudem immer Tagebuch ähnlicher wurde, lagerte ich diesen Abschnitt hierher aus. Er beschreibt die Änderungen, Anpassungen, Erkenntnisse, Ideen, die mich während der Arbeit an diesem Projekt beschäftigt haben und derzeit (s. obiges Datum) noch beschäftigen.
Es begann im Jahr 2018 nachdem in 2017 unsere ca. 10.000 Liter fassende Zisterne im Erdreich versenkt wurde und durch mehrere Auffangflächen sowie Rohrleitungen nebst Filter versorgt wird. Ich wollte ein Messsystem hierfür kaufen, welches mir den aktuellen Füllstand zeigt und die Messwerte speichert. Die Speicherung sollte eine Auswertung ermöglichen, um auf Grund der Erkenntnisse ggf. weitere Investitionen vorzunehmen, bspw. Anschluss von WC-Spülungen an die Zisterne.
Meine Recherche für ein solches speicherfähiges Messsystem war ernüchternd erfolglos. Also begann ich den langen Weg, ein solches System selbst zu bauen und zu programmieren - nicht ganz ohne geeignete Vorkenntnisse. Ich habe währenddessen einiges gefunden, verworfen und dazugelernt. ...
Aktuell verwende ich als Messsystem einen Mikrocontroller (µC) ESP32 mit der open Source Firmware Tasmota32 und der Programmiersprache Berry. Per Berry habe ich ein Anwendungssystem erstellt, welches sich auf den Unterbau Tasmota32 stützt.
Zum Einsatz kommen
- ein Entwicklungsboard mit dem o.a. µC ESP32 - Kosten: ca. 10 €
- ein Temperatursensor DS18B20 in zylindrischem Edelstahlgehäuse - Kosten ca. 4 €
- ein Ultraschallsensor JSN-SR04 zur Messung des Abstands zwischen Sensor und Wasseroberfläche - Kosten ca. 10 €
- ein Gehäuse IP67 mit transparentem Deckel, um bei Sichtkontrolle Feuchtigkeit im inneren erkennen zu können - Kosten ca. 10 €
- Silikon zum Abdichten der Kabeldurchführung (3 Kabel durch eine Bohrung) und des Gehäuses - Schraubdurchführungen sind hierfür ungeeignet
- ein paar Kleinteile wie Lötpunkt- oder Lötstreifen-Platinenabschnitt, Klingeldraht, Widerstände, Klemmen und evtl. Fädeltechnik
- Tasmota32, welches mit der angepassten Programmiersprache Berry relativ leicht programmierbare Erweiterungen zulässt und ein einfaches Dateisystem mitbringt
- ein Raspberry Pi der dritten Generation als Server-Host, voraussichtlich werde ich zukünftig einen Raspi 4 einsetzen - Kosten mit 1TB USB-SSD, Netzteil und kühlendem Gehäuse ca. 190 €
Der USB-SSD Speicher kann getrost durch eine bspw. 128GB SSD ersetzt werden die für ca. 27 € erhältlich ist. Eine µSD Karte oder ein USB Stick sind nicht empfehlenswert. Bei vorhandenem Raspi 3 oder höher und USB Platte kann selbstverständlich diese Kombination eingesetzt werden. - MQTT, demzufolge ein MQTT Broker, hier Mosquitto
- Node-RED bzw. Node-RED Flows als vielseitig einsetzbare Kommunikations- und Vermittlungszentrale für die IoT Kommunikation
Damit habe ich u.a. einen Flow zur Darstellung der Messreihen per Zeitfunktionsgrafiken erstellt. - die Android Smartphone App MQTT Dash zur Parametrierung des Messsystems, zum Ablesen der Messwerte, ...
- das Datenbank Managementsystem InfluxDB zur persistenten Speicherung der Messwerte, Version 1.8 - Version 2 ist derzeit nicht für Raspberry Pi verfügbar, und wohl für dieses Projekt auch nicht erforderlich
- die Anwendungszentrale openHAB, zunächst nur zum experimentieren und kennenlernen
Sämtliche eingesetzte Software ist legal kostenfrei verfügbar.
Zur einführenden Nutzung von Node-RED und MQTT Dash fand ich einen englischsprachigen Artikel. Node-RED taucht darin als "magicblocks" auf.
Bisher habe ich die Messwerte in Textdateien gespeichert. Dies löse ich aktuell durch die Verwendung von InfluxDB ab.
"Tagebuch" zur Entwicklung des Messsystems und dessen Nutzung
2021-07-29
Die Bereinigung der Rohwerte von fehlerbehafteten Rohwerten (Ausreißern) bedarf einer erheblichen Verbesserung.
Ein Messfehler: 2 von 12 Rohwerten liegen in starkem Maße unterhalb des Mittelwertes. Mein alter Algorithmus zur Bereinigung ist dafür ungeeignet.
Aufzeichnung: "distance":[148.544, 148.561, 148.526, 148.526, 148.561, 119.491, 148.561, 148.579, 148.544, 80.018, 148.544, 148.579]
Die beiden Fehlmesswerte sind unterstrichen.
2021-07-30
Beseitigung von Fehlmessungen
Ich denke, nach Recherche, über den medianen Mittelwert nach.
2021-07-31
Mittelwertbildung per Median implementiert - s.a. Debug-Auszug
Bei genauerer Betrachtung des Ablaufs meines Anwendungssystems bietet sich der Median als Mittelwert in besonderem Maße an. Die Rohwerte treffen in Abständen von ca. 3s ein. Dazwischen hat die empfangende Kommandofunktion sehr viel Zeit, sich mit einem importierten Rohwert zu befassen. Dieser wird per lineare Suche in die Rohwerte-Liste aufsteigend einsortiert (insertion sort). Da nur wenige Werte (5 bis 9) zur Mittelwertbildung gebraucht werden, habe ich keine binäre Suche implementiert. Nach dem Abschluss der kleinen Messreihe wird der mediane Mittelwert als Rohwert zur Weiterverarbeitung verwendet. Bei ungerader Anzahl an Rohwerten ist dies der in der Mitte liegende Wert. Bei gerader Anzahl wird das arithmetische Mittel aus dem Wert vor der Mitte und nach der Mitte verwendet - in der Mitte liegt ja kein Wert. Verlässt ein Wert am Rand der Liste (potentieller Ausreißer) den einstellbaren Toleranzbereich, wird eine MQTT Nachricht mit allen Rohwerten gesendet und, per Node-RED, auf dem MQTT Host für Analysebedarfe gespeichert.
Beispielauszug zu 2 Ausreißern in 11 Rohwerten:
[95.509, 151.86, 161.158, 161.158, 161.175, 161.193, 161.211, 161.211, 161.228, 161.246, 161.246],"median":161.193
Die beiden Ausreißer sind unterstrichen, der Median rot und fett dargestellt.
Bisher zeigten sich ausschließlich Ausreißer nach unten, also kürzere Abstände, was u.a. durch vor der Wasseroberfläche hängende Teile erklärbar wäre. Die Ursache für solche Ausreißer ist mir aber nicht bekannt. Ein im trockenen Raum als Experimentier- und Entwicklungssystem aufgestelltes Messsystem ohne reflektierende Hindernisse liefert auch solche Ausreißer. Für die Anzahl an Rohwerten zwecks finden eines fehlertoleranten Rohwertes ist 5 knapp bemessen, 7 bereits hinreichend stabil, 9 sehr gut und 11 fast übertrieben. Werte über 11 sind realitätsfern oder, falls erforderlich, einer ungünstigen Messumgebung geschuldet.
Wenn eine sorgfältige Analyse (wie bisher) zeigen sollte, dass ausschließlich Ausreißer zu kleineren Rohwerten (strukturelle Asymmetrie) und bspw. (fast) nie mehr als zwei von diesen sich ereignen, bietet sich eine spezifische Optimierung an. Dann kann eine Verschiebung des abgegriffenen Mittelwertes um eine Stelle nach hinten implementiert werden, also Wert an der Stelle Median+1. Dann wären 5 Rohwerte für eine Messung bereits hinreichend stabil. Sogar 3 Rohwerte wären mit kleinem Restrisiko möglich. Eine sehr kleine, einfache und hierfür geeignete KI könnte implementiert werden. Dies tue ich dann, wenn es sehr viele Abnehmer meines Systems gibt. 
Timing
Da jede einzelne Rohwertmessung ca. 3s dauert, brauchen bspw. 9 Rohwertmessungen ca. 27s. Die Dauern von Verarbeitungen und MQTT Veröffentlichungen liegen in der Größenordnung einer Zehntelsekunde und sind vernachlässigbar. Wenn jede volle Minute eine Messung (bspw. 9 Rohwertmessungen ...) durchgeführt werden soll, ist das System nur zur knappen Hälfte beschäftigt - der Garbage Collector soll ja auch nebenbei arbeiten können. 7 Rohwertmessungen sind bei sorgfältiger Anordnung des Ultraschall-Sensors deutlich mehr als hinreichend und "verbrauchen" nur ca. 21s. Zudem ist das Eintreffen der Rohwerte ereignisgesteuert und die Berry Funktionen können mit großer Zeitreserve in der Zwischenzeit abgearbeitet werden. So bleibt auch für Softwareerweiterungen dieses Systems noch viel Spielraum.
2021-08-02
Analyse der Häufigkeit von Abstands-Rohwertfehlern
Analyserahmen: 34 Stunden dauernde Aufzeichnungen, je Messung 11 Abstandsrohwerte, Messungen in 2 minütigen Abständen
In dieser Zeitspanne wurden 1020 Messungen durchgeführt. Es traten 99 Messungen mit mindestens einem Rohwertfehler auf, was knapp 3 fehlerbehaftete Messungen pro Stunde sind bzw. im Mittel weist ca. jede zehnte Messung mindestens einen Rohwertfehler auf.
In genau einem Fall gab es drei Rohwertfehler, sonst zumeist eine und weniger oft zwei solche Fehler. Alle Rohwertfehler liegen unterhalb des Medianwertes, also bei aufsteigender Sortierung an den ersten Stellen. Der kleinste Positionsabstand zwischen dem Median und dem ihm am dichtesten gelegene Rohwertfehler wähle ich als kritisches Maß. Dieser Abstand beträgt in dieser Analyse 3 und ist somit unkritisch. Als kritisch werte ich einen Abstand von 1, weil dann kein fehlerfreier Rohwert zwischen dem Median und dem dichtesten Fehlerwert liegt.
Die Rohwerte mit den drei einsortierten Fehlerwerten: [131.298, 153.246, 156.175, 161.228, 161.246, 161.246, 161.246, 161.246, 161.246, 161.281, 161.298] - Fehlerwerte unterstrichen, Medianwert rot und fett
Aus diesem Zwischenergebnis folgt vorläufig, dass bei Verwendung des Median mindestens 7 Rohwerte zu erfassen sind. Die oben beschriebene spezifische Optimierung würde greifen und damit wären mindestens 5 Rohwerte je Messung erforderlich.
Am Beispiel der bisher einmalig aufgetretenen dreimaligen Rohwertfehler ergäbe sich mit dieser, noch nicht implementierten, Optimierung prinzipiell folgende Konstellation:
[131.298, 153.246, 156.175, 161.228, 161.246] - Rohwertfehler unterstrichen, (Median+1)-Wert rot und fett. In diesem hypothetischen Fall wäre der kleinste Positionsabstand mit 1 allerdings kritisch.
Ein alternativer spezieller Algorithmus, zu welchem meine Frau in einem Gespräch die Grundidee hatte, werde ich vielleicht noch testweise implementieren. Bisher bewährt sich aber der Median sehr gut. Auch für den Fall, dass sich während der Rohwertmessungen der Wasserstand verändert, ist der Median als Mittelwert gut geeignet. Die zur Analyse erfassten Fehlmessungen sind nicht auf eine solche Veränderung zurückzuführen, weil sich der Füllstand in der Realität nicht derart schnell verändert, weder durch Wasserentnahme noch durch Zufluss. Vielleicht könnte ein extrem starker Regen einen sehr schnellen Zufluss ergeben, dies ereignete sich aber während der Aufzeichnungszeitspanne nicht.
2021-08-03
Weitere Analyse von Abstands-Rohwertfehlern
Analyserahmen: 68h+20min, je Messung 11 Abstandsrohwerte, Messungen in 2 minütigen Abständen
2050 Messungen, 180 mal mit mindestens einem Rohwertfehler, insgesamt 3 mal mit 3 Fehlern, alle Fehler unterhalb des Medianwertes
Der Gesamteindruck aus der ersten Analyse ist im wesentlichen bestätigt. Ich werde die Anzahl an Rohwerten je Messung auf 7 reduzieren und eine neue Speicherung starten.
Eindrücke und Erfahrungen als ambitionierter Anwender
In den gespeicherten Nutzwerten treten keine Ausreißer mehr auf. Die auf Grund von Änderungen, also mit dem Trigger "differ", gespeicherten Nutzwerte benötigen bisher ca. 1/8 an Speicherkapazität im Vergleich zu denen der stündlichen Speicherung per "sample". Dabei werden Änderungen von über 20 Liter erfasst und dies alle 2 Minuten geprüft. In einer ca. 10.000 Liter fassenden Zisterne ist dies eine relative Auflösung von 0,2%. Noch erscheinen die Grafiken aus der stündlichen Speicherung (Trigger "sample") vertrauter als die aus der Änderungsspeicherung (Trigger "differ"). Vielleicht wird sich dies zukünftig noch ändern. Die "differ" Grafik liefert jedenfalls feinere Verlaufsinformationen.
2021-08-04
Ich habe die Grafik verbessert, welche auf der Speicherung per Trigger "differ" basiert, also auf hinreichend großen Änderungen des Wasservorrates/Füllstandes. Sie bietet nun eine geeignete Darstellung der Dynamik von Füllstandsänderungen - s.a. obige Abbildung - dort unter dem Titel "für genauere Betrachtungen".
Grobe Zwischenanalyse der gespeicherten Rohwertfehler:
Interessanterweise treten anscheinend bei nur 7 Rohwerten per Messung seltener fehlerbehaftete Messungen auf als bei 11 Rohwerten. Dies lässt evtl. auf eine über längere Zeitspannen etwa Gleichverteilung von Rohwertefehlern schließen.
Folgerung: Irgendwo könnte es ein Optimum für die Anzahl an Rohwerten je Messung geben. Zumindest ist es vermutlich keineswegs besser, eher suboptimal, diese Anzahl an Rohwerten sehr groß zu wählen, bspw. über 11.
Ich werde weitere Analysen dazu betreiben.
Heute habe ich eine Sichtprobe der Messelektronik in der Zisterne durchgeführt. Die Elektronik "wohnt" seit dem 2021-07-19 in der Zisterne. Der Ultraschallsensor sitzt hinreichend fest, im Elektronikgehäuse sind durch die transparente Abdeckung keinerlei Feuchtigkeitsspuren zu sehen. Ich bin zuversichtlich, dass hier in den nächsten Monaten und hoffentlich Jahren keine Feuchtigkeit eindringen wird.
Ein Gedanke: Vielleicht ist der mehr oder weniger feste Sitz des Ultraschallsensors mit für die festgestellten Rohwertfehler ursächlich. Für genauere Untersuchungen dazu fehlt mir die Laborausstattung und geeignete Assistenz.
2021-08-05
Analyse von Abstands-Rohwertefehlern
Analyserahmen:
2021-08-03 14:36 Uhr (erster Fehlereintrag) bis 2021-08-05 14:48 Uhr, das sind über 48h 12min, weil ich die Startzeit nicht notiert hatte.
Je Messung 7 Rohwerte, Messungen in 2 minütigen Abständen
Über 2893 Messungen, davon 35 Messungen mit 1 Rohwertfehler und 2 Messungen mit 2 Rohwertfehlern, keine Messung mit mehr als 2 Rohwertfehlern, unter 1,28% Messungen mit Fehlern, kleinster Positionsabstand = Positionsabstand Median - dichtester Rohwertfehler = 2
Vergleich mit obiger Analyse vom 2021-08-02: Bei 11 Rohwerten je Messung gab es ca. 10% Messungen mit Fehlern. Darunter gab es 3 Messungen mit 3 Rohwertfehlern, kleinster Positionsabstand = 3
Einer der beiden Datensätze mit 2 Fehlern: {"time":"2021-08-05T09:04:00","tolerance":2,"raw":[58.07, 80.895, 136.474, 136.509, 136.526, 136.579, 136.737],"median":136.509}
Somit sind 7 Rohwerte je Messung erheblich weniger fehlerlastig als 11 Rohwerte je Messung. Der kleinste Positionsabstand ist bei 7 Rohwerten je Messung mit 2 unkritisch, auch wenn er um 1 kleiner ist als bei 11 Rohwerten je Messung.
Ich starte eine weitere Analyse mit 5 Rohwerten je Messung. Startzeit: 2021-08-05 15:03 Uhr
Ich bin auf RRDtool aufmerksam geworden, einem Mehrfach-Ringspeicher Datenbanksystem. In openHAB steht rrd4j (RRD for Java) zur Verfügung. Vielleicht werde ich mich genauer damit beschäftigen. RRDtool besitzt jedenfalls ein hochinteressantes Konzept zur Speicherung von Daten in begrenzten und konfigurierbaren Bestandteilen einer Wertedatenbank. Die Größe der Datenbank steht von Beginn an fest und ändert sich nicht. Die neueren Werte werden unverändert gespeichert. Die älteren Werte werden geeignet nach Wahl komprimiert, bspw. per Mittelwertbildung. Das passt meiner Ansicht nach recht gut zum speichern von Messwerten und erstellen von Grafiken - auch für große Zeiträume.
Problem: Es gibt noch anderes und oftmals wichtigeres im Leben. 
2021-08-06
Dynamischer arithmetischer Mittelwert - ein Versuch
Voraussetzung: Alle Abstands-Rohwerte liegen aufsteigend sortiert in einer geordneten Liste vor. Dies ist bereits implementiert.
Bisher habe ich den Median als den geeigneten Mittelwert aller während einer Messung gesammelten Rohwerte verwendet. Es geht vermutlich noch etwas besser. Ich nenne den neuen Mittelwert "Dynamischer arithmetischer Mittelwert". Dieser ergibt sich als der Wert aller, gemäß parametrierter Toleranz, nicht fehlerbehafteter Rohwerte - kurz: aller "guten" Rohwerte. Da die Toleranz eine Referenz braucht, würde ich im Normalfall zunächst den Median als Referenz wählen. Mit Normalfall meine ich, dass die geordnete Liste an Rohwerten prinzipiell eine symmetrische Struktur aufweist. D.h. sowohl am Anfang der Liste als auch an deren Ende können Ausreißer auftreten. Dies ist hier aber nicht der Fall.
Nach einigen umfangreichen Analysen von Rohwerten mit Ausreißern zeigt sich, dass Ausreißer ausschließlich am Anfang der Liste auftreten. Deshalb wähle ich als vorläufige Referenz den letzten Wert in der Liste. Von diesem ausgehend wird in Richtung Listenanfang sukzessive der sich verändernde arithmetische Mittelwert als dynamische Referenz gebildet. Dies geschieht, solange der Wertabstand des nächsten Listenelements zum aktuellen Mittelwert innerhalb der parametrierten Toleranz liegt, das nächste Listenelement also nicht als Ausreißer kategorisiert wird.
Auf diese Weise erhalte ich den arithmetischen Mittelwert aller "guten" Werte. Zusätzlich kann damit auch die Anzahl an "guten" Werten ermittelt werden. Ist diese zu klein, kann eine simple KI die Anzahl an Rohwerten je Messung erhöhen. Eine Strategie zur Verkleinerung der Rohwerteanzahl habe ich noch nicht. Diese ist vermutlich auch nicht erforderlich, wenn bspw. mit 5 Rohwerten begonnen wird. Dann wird irgendwann keine Vergrößerung der Anzahl an Rohwerten mehr stattfinden und eine stabile Mittelwertbildung erreicht sein. So wird die Anzahl an Rohwerten je Messung nicht größer als notwendig. Diese simple Strategie kann mit jedem Systemneustart begonnen werden und benötigt auf diese Weise keine Persistenz.
Als unkritisch wähle ich die Majorität der guten Werte gegenüber den schlechten Werten. Liegt ein kritischer Fall vor, d.h. die guten Werte sind gleichviele oder weniger als die schlechten Werte, wird die Anzahl an Rohwerten je Messung um 1 erhöht. Für Härtetests werde ich den Anfangswert auf 3 Rohwerte je Messung setzen. Weniger ist sinnfrei.
Diese Implementation wird gegenwärtig auf einem gleich aufgebauten System seit 15:05 Uhr getestet. Nachdem bis 19:00 Uhr nur ein Ausreißer festgestellt wurde, habe ich die Anzahl an Rohwerten testweise auf 2 reduziert.
Neuer Teststart um 19:11 Uhr
Wenn sich keine neuen Erkenntnisse einstellen, werde ich die Anzahl an Rohwerten je Messung auf 4 setzen. Ich erwarte, dass sich dieser Wert erst nach einigen Tagen oder gar Wochen auf 5 erhöhen wird. Länger als ein paar Tage will ich diesen Test aber nicht laufen lassen.
Analyse des Testlaufs auf dem Zisternenmesssystem, Start 2021-08-05 15:03 Uhr, aktuelle Zeit 19:27 Uhr, 5 Rohwerte je Messung, Median als Mittelwert
28 Stunden + 24 Minuten, 10 Messungen mit je 1 Ausreißer, keine mehrfachen Ausreißer, im Mittel ca. jede 170. Minute ein Ausreißer
2021-08-07
Seit heute läuft auf dem µC in der Zisterne eine Testversion vor Version 1.4 mit dem Algorithmus "dynamischer arithmetischer Mittelwert" und der simplen KI zur Erhöhung der Anzahl an Rohwerten je Messung, falls die guten Werte nicht die Majorität haben.
Definitionen für diesen Algorithmus incl. KI:
- Dist = distances, geordnete Liste an Abstandsrohwerten, auch fehlerbehafteten
- R = raw value, Abstands-Rohwert - davon gibt es zu jeder Abstandsmessung eine zunächst festgelegte Anzahl. R ist Element aus Dist.
- A = average, Durchschnitt = dynamischer arithmetischer Mittelwert aller "guten" Rohwerte
- T = tolerance, Toleranz als Benutzer definierter Parameter, an Hand dessen festgestellt wird, ob ein Wert ein Fehlerwert ist. Dann und nur dann, wenn |A-R|>T ist, wird R als Fehlerwert kategorisiert.
- Rn = raw value number, Anzahl an Abstandsrohwerten je Messung. Dieser ist eine natürliche Zahl mit dem Mindestwert 2.
Rn ist derzeit ein einstellbarer Parameter, der mit der Festlegung (schreiben) und nach jedem System-Neustart übernommen wird. Rn kann sich auf Grund der KI stufenweise geringfügig erhöhen.
Für Testphasen definiere ich noch Werte, die auf die Qualität der Messungen schließen lassen:
- N = Anzahl an Messungen in einer Testphase
- P = payload, mittlerer Nutzwert, hier mittlerer Wasservorrat in Liter
- Fn = failure number, Anzahl an insgesamt aufgetretenen Rohwertfehlern
- Fnh = failure number per hour, Anzahl an Rohwertfehlern je Stunde
- dR = difference raw value, Differenzbetrag zwischen maximalem und minimalem gemitteltem Rohwert (Abstand) in einer Phase ohne Wasserzufuhr
- dP = difference payload, Differenzbetrag zwischen maximalem und minimalem Nutzwert (Wasservorrat) in einer Phase ohne Wasserzufuhr
Der Testlauf ist zugleich der praktische Einsatz ohne Abstriche. Hier werden nur zwecks Analyse je Messung zusätzliche Daten protokolliert.
In einer Datei "raw" wird je Messung der Zeitstempel, die Toleranz T, die Liste Dist aller Rohwerte und der Mittelwert A aller guten Rohwerte gespeichert.
In einer Datei "proc" wird je Messung der Zeitstempel, die Triggerliste (hier unerheblich) sowie die Nutzwerte Temperatur und Wasservorrat gespeichert.
Per "raw"-Werte ist ablesbar, wieviele Rohwerte erfasst werden (Rn), welche Ausreißer es gibt und welcher arithmetische Mittelwert A sich daraus ergibt.
Per "proc"-Werte sind insbesondere Schwankungen des gemessenen Wasservorrats in Phasen ohne Wasserzufuhr ablesbar, also die Messtoleranz dP dieses Nutzwertes.
Beginn: 05:52 Uhr, Start-Rn = 4, T = 2.0 cm, "differ"-Messabstand = 2 Minuten
Zwischenstand um 10:52 Uhr: keine Wasserzufuhr, N = 151, Fn = 3, Fnh = 0.6, dR = 0.382 cm = 3.82 mm, dP = 18 Liter, P = 5067 Liter, Rn = 4
In Prosa:
Während der Testphase ohne Wasserzufuhr gab es 151 Messungen, darin 3 Fehler in den Abstands-Rohwerten.
Die gemittelten Rohwerte schwankten um maximal 3.82 mm. Die gemessenen Werte des Wasservorrats schwankten um maximal 18 Liter.
Die Anzahl an Rohwerten je Messung ist am Ende der Testphase 4, d.h. sie wurde nicht verändert.
Eine Schwankung der gemessenen Abstands-Rohwerte ohne Ausreißer von 3,8 mm bzw. Nutzwertschwankung von 18 Liter ergibt einen relativen Nutzwert-Messfehler von ±9 Liter / 5067 Liter = ± 0,18 %.
Noch besser liegt der relative Fehler auf das Fassungsvermögen der Zisterne von rund 10.000 Liter bezogen. Dieser ist nur ±9/10000 = ±0,09%.
Mit dieser Messgenauigkeit bin ich mehr als zufrieden.
Anmerkungen zur kleinen KI und deren Folgen
Hier geht es nicht um eine fortlaufende Optimierung des Messsystems sondern darum, bei auftretenden unerwartet hohen Dichten an Rohwert-Messfehlern die Robustheit der Messungen aufrechtzuerhalten. Es handelt sich hierbei also ausschließlich um eine Maßnahme zur Stärkung der Verlässlichkeit der gelieferten Nutzwerte. Eine geänderte Anzahl an Rohwerten je Messung (Rn) um mehr als 2 lässt auf Messprobleme schließen und kann als Indiz für einen Wartungsbedarf genutzt werden.
Kann Starkregen die Messungen stark beeinträchtigen?
Damit die KI nicht zu oft durch Starkregen aktiv wird, können die bisherigen Analysen zu Rate gezogen werden. Ein vermutlich guter Wert für den Parameter Toleranz liegt ca. 1,5 cm oberhalb des max. Anstiegs durch Zulauf in 3s. Dieser Wert hängt von den Vor-Ort-Gegebenheiten des Wasserauffangs ab. Dies sind
- die maßgebende Querschnittsfläche des Zulaufsystems - oftmals ist das die kleinste, bei verzweigten Zuläufen gleichen Durchmessers die letzte Querschnittsfläche vor oder in der Zisterne
- die maximale freie Fließgeschwindigkeit von Wasser im Zulaufsystem, also ohne zusätzlichen Druck. Bis auf weiteres nehme ich hierfür den Größenordnungswert von 1m/s an.
- der per Zulauffilter der Zisterne zugeführte Anteil - bei Starkregen ist dieser, je nach Filteraufbau, relativ nahe an 1. Somit kann für diese Berechnung der Filtereigenverbrauch bei Starkregen vernachlässigt werden.
- in die waagerechte Ebene projizierte Auffangfläche ist nur bei kleinen Flächen von Belang, ansonsten ist die Querschnittsfläche des Zulaufsystems alleine als begrenzend maßgebend
Die Simulation eines Starkregens zur empirischen Erfassung des max. Anstiegs in 3s wird in den meisten Fällen zu aufwändig sein. Dann ist es zweckdienlicher, den max. Zulauf in 3s wenigstens abzuschätzen.
Die Formel lautet dV/dt = v • A mit dV/dt = Volumenänderung je Sekunde, v = maximale freie Fließgeschwindigkeit von Wasser, A = maßgebende Querschnittsfläche des Zulaufsystems
Beispiel zur Ermittlung eines Orientierungswertes - ich habe bisher noch keine einschlägigen Erfahrungen:
Ich nehme wegen der Bremswirkung der Zuführungsleitungen und insbesondere des Zulauffilters v = 1m/s an, ein Wert für fließendes Wasser in Flüssen.
Rohrdurchmesser des Zulaufs d = 10 cm ist vermutlich ein übliches Maß.
Auffangfläche groß, d.h. nur die Querschnittsfläche der Zuführung begrenzt den Zufluss bei Starkregen.
Verringerung durch den Zulauffilter wird wegen max. Zulauf vernachlässigt.
Daraus ergibt sich dV/dt = 10 dm/s • (1dm)2 • π/4 = ca. 7,85 Liter/s. Dieser Wert soll für viele Zisternensysteme eine brauchbare Orientierung bieten.
Für die daraus resultierende Abstandsänderungsgeschwindigkeit dD/dt (D=Distanz, t=Zeit) ist die Wasseroberfläche Az (A Zisterne) heranzuziehen, weil sich der Zulauf auf die Fläche verteilt.
In meiner Zisterne ist der Innendurchmesser 258 cm.
Az = (25,8dm)2 • π/4 = 522,8 dm2 = ca. 5,2 m2
dD/dt = dV/dt • 1/Az) = ca. (7,85 dm3/s) / (522,8 dm2) = ca. 0,015 dm/s = ca. 1,5 mm/s - erstaunlich wenig, hoffentlich stimmt meine Berechschätzung
In 3s, so groß ist die Zeitdifferenz zwischen zwei Messungen etwa, ergibt sich durch Starkregen eine vermutete Distanzänderung (Rohwert) dD von ca. 0,45 cm.
Die Toleranz sollte auf der Basis obiger Berechnungen und vorgelagerter Analysen bei etwa 2 cm liegen. Diesen Wert habe ich in meinen Tests bereits verwendet. Der von mir implementierte Algorithmus kann bei Starkregen, trotz aller Sorgfalt in der Toleranz-Parametrierung, einen guten Rohwert als Ausreißer kategorisieren - insbesondere dann, wenn er in der geordneten Liste im Anfangsbereich liegt. Dies halte ich aber für unkritisch. Die KI schwächt mit der Erhöhung der Anzahl an Rohwerten je Messung die für die Messung unerwünschte Wirkung eines Starkregens ab, weil der dynamische arithmetische Mittelwert sich auf mehr einzelne Rohwerte stützt. Das ist, nebenbei bemerkt, ein Argument für diesen Algorithmus.
Zumindest bleibt die Erkenntnis, dass bei meinen, nicht unüblichen, Gegebenheiten ein Starkregen nur zu etwa 1/3 in die Toleranz einfließen dürfte. Im Laufe der Nutzung gesammelte Erfahrungen werden dies abrunden. Starkregen kommen in meiner niederschlagsarmen Lokation relativ selten vor. Bei einer Überschwemmung bleibt zu hoffen, dass ein nicht mehr ordnungsgemäß arbeitendes Messsystem das größte Problem ist. Dieses ist dann sehr leicht durch einen Neustart zu lösen.
Nach-gedacht
Evtl. kann eine unsymmetrische Toleranz, also aus zwei Werten bestehend, nützlich sein.
Beispiel: obere Toleranzschwelle To = +1,5 cm, untere Toleranzschwelle Tu = -2,5 cm
Mit der Sortierung der Rohwerte wird die Mittelwertbildung und das Finden von Ausreißern unterstützt. Zugleich geht aber die Historie während einer Messung verloren. Es kann somit die Tendenz einer evtl. Füllstandsänderung nicht mehr erfasst werden. Eine Zweigleisigkeit der temporären Rohwertspeicherung könnte die KI stärken, weil sie die Historie berücksichtigen könnte. Die Implementierung einer solchen stärkeren KI erscheint mir allerdings nicht trivial. Mal sehen ...
2021-08-08
Analyse der Rohwerte
Analyserahmen: 2021-08-07 05:52 Uhr bis 2021--08-08 17:01 Uhr, dynamischer arithmetischer Mittelwert mit simpler KI, je Messung 4 Rohwerte, Toleranz = 2cm
1055 Messungen, davon 24 mit je einem Ausreißer unterhalb der guten Werte, keine Mehrfachausreißer, die Ausreißer liegen zeitlich sehr ungleich verteilt, am Ende unverändert 4 Rohwerte je Messung
In der längsten Phase gleichbleibenden Wasservorrats von ca. 5000 Liter schwanken die Werte um maximal 19 Liter.
Die "sample"-Grafik mit den Nutzwerten zeigt etwas geringere Schwankungen bei unverändertem Füllstand im Vergleich zum Median-Mittelwert. Das kann Zufall sein, wäre aber bei systematischer Ursache plausibel.
Fazit: Bisher bewährt sich der neue Algorithmus.
2021-08-11
Seit 2021-08-07 05:47 Uhr läuft das Messystem ohne Unterbrechung, um diese Firmwareversion ausgiebig zu testen. Der Parameter Anzahl an Rohmesswerte je Messung ist im nichtflüchtigen Speicher auf 4 gesetzt. Das Anwendungssystem hat am 2021-08-09 16:32 Uhr, nach 1761 Messungen diese Anzahl im Arbeitsspeicher auf 5 erhöht, weil in einer Messung erstmalig 2 Ausreißer auftraten. Selbstverständlich kann diese Anzahl im nichtflüchtigen Speicher auf 5 gestellt werden. Dieser Testlauf soll aber prüfen, ob sich der Algorithmus bewährt. Es ist geplant, diesen Test eine Woche lang laufen zu lassen, solange sich kein Neustart wegen Stromausfall ereignet.
2021-08-17
Wesentliche Analyse-Ergebnisse des Testlaufs.
Beginn: 2021-08-07 05:52 Uhr, Start-Rn = 4, T = 2.0 cm, "differ"-Messabstand = 2 Minuten
Aktuell: 2021-08-17 19:10 Uhr
Die Zeitspanne dieses Testlaufs beträgt aktuell ca. 10,5 Tage.
Die Anzahl an Rohwerten Rn setzt sich täglich um 00:07 Uhr auf den persistenten Wert zurück, hier 4. Dies bewirkt eine der Rules im Ruleset 1, die ich zur Datensicherheit einsetzte. Im Nachhinein betrachtet, ist sie ein einfaches und geeignetes Mittel, erhöhte Ausreißerdichten feststellen zu können.
In einem ggf. noch länger andauernden Testlauf werde ich diese Rule temporär entfernen. Ein solcher Testlauf ist zunächst nicht geplant.
Rn=4 bleibt mitunter über mehrere Tage erhalten, kann sich aber auch an zwei hintereinander liegenden Tagen jeweils auf 5 erhöhen. Rn=6 kam nicht vor. Insgesamt wurde an 4 Tagen Rn von 4 auf 5 erhöht. In den Nutzwerten "Wasservorrat" gab es keinen Ausreißer.
Fazit
Der "Dynamische arithmetische Mittelwert" bewährt sich. Die kleine KI zur Erhöhung von Rn um jeweils 1 bei höheren Ausreißerdichten ("gute" Werte haben nicht die Majorität) bewährt sich.
In meiner Messumgebung ist der persistente Wert Rn=4 ausreichend. In üblichen Betriebsfällen sollte Rn=5 völlig genügen und die KI diesen vermutlich nur sehr selten auf 6 erhöhen. Ich plane, bei einer Erhöhung um insgesamt 2 einen Warnhinweis senden zu lassen.
2021-08-20
Der vorerst letzte Testlauf
In diesem Testlauf arbeitet eine Arbeitsversion zwischen 1.3 und 1.4. Das Messsystem ist dabei im produktiven Einsatz, nur das Protokollieren der Rohdaten ist zusätzlich aktiviert. Der Warnhinweis nach Erhöhung von Rn um 2 ist noch nicht zufriedenstellend implementiert, weil ich zu Version 1.4 einen Umbau des Quellcodes vornehmen will. Täglich werden um 00:07 Uhr alle persistenten Parameter in den flüchtigen Datenspeicher kopiert, so u.a. auch der Startwert von Rn.
Aktuelle Parameter: Start-Anzahl an Rohwerten Rn=4, Toleranz T=2.0cm, kürzester Messabstand dt=2 Minuten
Rn=4 ist ein Parameterwert für den Testlauf. Diesen werde ich voraussichtlich nach diesen Tests auf 5 einstellen. Es ist zu erwarten, dass die KI diesen Wert in einer ungestörten Umgebung nie oder fast nie auf 6 vergrößern wird.
Start: 2021-08-19 17:12 Uhr
Ende voraussichtlich erst, wenn ich den Quellcode für Version 1.4 umbaue und den Warnhinweis bei vermehrt auftretenden Ausreißern zufriedenstellend implementiere. Zwischenzeitlich werde ich die Entwicklung von Rn beobachten.
2021-08-22
Arbeit mit InfluxDB
Die Daten werden zunächst zusätzlich in einer InfluxDB Datenbank gespeichert. Diese Speicherung liegt zwar etwas außerhalb des Fokus Zisternen-Messsystem, die Optionen des Datenbanksystems tragen aber zu einer angemessenen Verbesserung meines Messsystems bei.
Beispiel
Angenommen es wird auf eine Lokalisierung Wert gelegt, d.h. bspw. die Namen der Messwerte sollen in der genutzten Muttersprache lauten. Mit InfluxQL, einer SQL ähnlichen Sprache, lassen sich Werte unter alias Namen abfragen. Damit ist eine Lokalisierung solcher Namen möglich. Zugleich habe ich im Messsystem auch eine solche Lokalisierung vorgesehen. Soll das Messsystem ohne Datenbank/Speicherung genutzt werden, ist die Lokalisierung im Messsystem zu verwenden. Bei Nutzung von InfluxDB kann die Lokalisierung dort eingesetzt werden.
Anwendung: SELECT time AS "Zeitpunkt", temperature AS "Temperatur", water_reserve AS "Wasservorrat" FROM "cistern" TZ('Europe/Berlin')
Hiermit werden alle Werte der Messreihe (measurement) "cistern" der genutzten Datenbank unter den Namen "Zeitpunkt", "Temperatur" und "Wasservorrat" geliefert. Außerdem wird die lokale Zeit (TZ=timezone) geliefert. Der Name der Messreihe "cistern" kann aber nicht per InfluxQL lokalisiert werden. Bei Bedarf muss dies an anderer Stelle, bspw. in einem Node-RED Flow erfolgen. Dieses Beispiel soll verdeutlichen, dass ein Blick über den "Tellerrand des Messsystems" nützlich ist.
Es ist noch nicht entschieden, ob der vom Messsystem gelieferte Zeitpunkt in die Messreihe einfließen soll. Ich favorisiere dies, weil das Messsystem am besten "weiß", wann es die Messung gestartet hat. Außerdem ist in dieser Anwendung die zeitliche Auflösung von InfluxDB in Nanosekunden irrwitzig. Ich experimentiere noch damit.
Das Messsystem soll in jedem Fall auch weitgehend autark, d.h. hier ohne viele zusätzliche Server genutzt werden können. Prinzipiell genügen nach wie vor ein MQTT Broker und ein Smartphone zum Ablesen der Werte.
2021-08-24
Änderungen an der Messanwendung-Software
Die Festlegungen der bevorzugten Messwerte-Benennungen (Lokalisierungen), bspw. in der Muttersprache, ist in eine Berry-Datei ausgelagert. Die Gründe dafür sind:
- Es können bei Bedarf mehr Messwerte-Namen festgelegt werden.
- Es werden zwei MEM-Speicherplätze frei, die zukünftig für Parametrierungen nutzbar sind.
- Da diese Messwerte-Namen auch gespeichert werden können - in einer InfluxDB Datenbank als "field keys" oder/und in einer Textdatei, sollten sie möglichst nur anfangs festgelegt und nicht mehr geändert werden.
- Parameter in den MEM-Speicherplätzen sind auf 32 Zeichen begrenzt, während die Messwerte-Namen in der Berry-Datei erheblich länger sein dürfen.
Der Zeitstempel wird vom Messsystem nun nicht mehr unter dem Namen "time" sondern unter "srctime" (source time) gesendet. Dies vermeidet Konflikte mit der InfluxDB-Benennung "time" für den intern gesetzten Zeitstempel. Beide Zeitstempel können in einem Datensatz enthalten sein.
Arbeit mit InfluxDB
Weil in dieser Anwendung das Messsystem selbst zeitgesteuert arbeitet, überträgt es den Zeitstempel unter dem Namen "srctime", von source time. Dies vermeidet Konflikte mit der InfluxDB internen Benennung "time" für den Zeitstempel zum Zeitpunkt des Eintragens in die Datenbank. Dieses Datenbank Management System (DBMS) unterstützt die Analysen der vom Messsystem gelieferten Werte auf übersichtliche Weise. Ich werde es weiterhin einsetzen. Vielleicht werde ich sogar meine bisherigen Speicherungen in Textdateien fallen lassen. Dazu hat u.a. Uwe Berger mit seinen Vorträgen auf der FrOSCon beigetragen. Er baut seine Vorträge sehr gut auf und stellt seine Folien zur Verfügung.
2021-08-25
Die ersten Zeitfunktions-Grafiken per Node-RED und InfluxDB stehen zur Verfügung. Mir gefallen sie. Grafana kann noch warten.
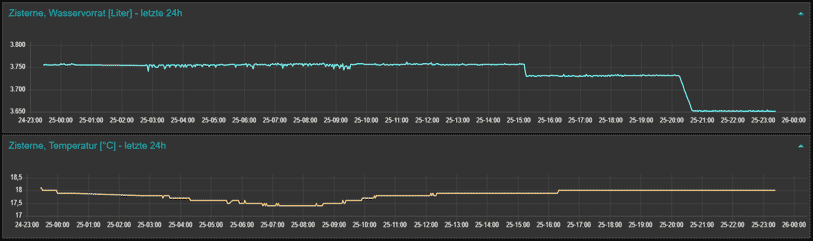
Die kleinen Schwankungen sind Messungenauigkeiten geschuldet. Sie betragen im Wasservorrat bis zu ca. 20 Liter, was bei ca 3700 Liter eine max. relative Messtoleranz von ca. 0,5% bzw. ca. ±0,25% ergibt. Vielleicht kann die Messtoleranz mit einem sehr kostspieligen Sensor verbessert werden. Mir genügt diese Toleranz bei weitem.
Ich arbeite mich in InfluxDB ein. Nach meinen bisherigen Erkenntnissen/Vermutungen/Planungen besitzt die reine Persistierung der Messwerte eine sehr einfache Struktur. Ich brauche bisher nur eine nützliche Persistierung mit Beschränkung des Datenbank-Umfangs.
Innerhalb einer dafür angelegten Datenbank liegen die Messreihen (measurements) in einem einfachen Ableitungs-Baum. Der Ursprung dieses Baums, also die Wurzel, ist die Messreihe "Nutzwerte". Die davon abgeleiteten per Mittelwertbildung komprimierten Messwerte liegen in den darunter legenden Ebenen, also als Kinder, Kindeskinder, ... vor. Entgegengesetzt der biologischen Väter, Kinder, Enkelkinder, ... sind die komprimierten Werte der Baumkinder älter als die ihrer Baumväter. Die Wurzel enthält also die jüngsten Werte. Diese werden jeweils durch eine "Continuous Query" (CQ) aus der unmittelbar darüber liegenden "Vorfahr"-Messreihe gebildet. Die in einer "Vorfahr"-Messreihe nicht mehr benötigten, älteren Werte werden per "Retention Policy" (RP) entfernt. Damit wird letztlich der Datenbank-Umfang beschränkt. Ältere Werte sind durch sukzessive Mittelwertbildungen in den "Nachfahr"-Messreihen komprimiert, bieten aber noch die Möglichkeit, diese per Grafiken darzustellen.
Auf eine Ebene projiziert ergibt sich folgender Graf: Nutzwerte → Nutzwerte_1 → Nutzwerte_2 → Nutzwerte_3 ...
"Nutzwerte" ist gleichbedeutend mit "Nutzwerte_0". Nutzwerte_<i> wird von Nutzwerte_<i-1> abgeleitet, wenn i>0.
Eine solche Struktur existiert meiner Kenntnis nach nicht in einer InfluxDB Datenbank. Es handelt sich vielmehr um eine virtuelle Struktur bzw. ein Denkmodell, das es mir erleichtert, die CQ und RP zu planen und zusammenzustellen. Ich bevorzuge diese Benennungen, weil ich damit im Namen nicht kennzeichnen will, wie lange die Werte darin aufbewahrt werden sollen oder in welcher Zeitspanne die Werte zusammengefasst sind. Diese Parameter werden durch die RP und CQ festgelegt und können bei Bedarf geändert werden, ohne dass dabei die Messreihen-Namen (measurement names) unpassend werden.
So ist jedenfalls mein Plan. Ich bin zuversichtlich, dass ich auf einem geeigneten Weg bin.
2021-08-26
Enttäuschung ...
Ich setze sicherheitshalber weiterhin, zumindest zusätzlich, auf die Datenspeicherung in Textdateien. InfluxDB ist sehr interessant und bietet genau die Möglichkeiten, die ich im Messprojekt brauche. Aber ...
Inzwischen habe ich InfluxDB auf meinem Rasperry Pi 3 mehrmals neu installieren müssen, weil dieser Sch... Dienst partout nicht starten wollte. Es sieht stark nach Problemen beim Einlesen der Datenbanken aus. Jede Neuinstallation war erst dann erfolgreich, wenn ich das komplette InfluxDB Datenverzeichnis zuvor löschte. Das ist sehr enttäuschend. Ich muss mich mit dem Sichern und Wiederherstellen von InfluxDB Datenbanken beschäftigen. Das gibt mir allerdings keine Datensicherheit, weil dieser Service offensichtlich die eigenen Datenbanken mitunter nicht "verdauen" kann und dann schlicht nicht startet. Eigentlich ist ein Nichtstarten wegen einer vielleicht inkonsistenten Datenbank für mich absolut unverständlich, es sei denn, es handelt sich um die System-Datenbank "_internal". Diese sollte allerdings von diesem Dienst besonders Fehler vermeidend behandelt werden. Ich habe dieses Problem vielfach in Webforen gefunden. Es ist seit Jahren präsent. So etwas kennzeichnet keine Qualität. Ich bin sehr verunsichert - schade.
Ich werde also parallel das Persistieren in Textdateien und das Komprimieren per Mittelwertbildung ohne InfluxDB betreiben müssen. Auf relationale Datenbanken habe ich für die Speicherung von Messwerten keine Lust, weil solche Datenbanken schlicht darauf nicht spezialisiert sind. Bisher arbeitete der Raspi 3 mit Mosquitto und Node-RED sehr, sehr zuverlässig. Er lief monatelang ohne Probleme durch. Meine Versuche mit der Speicherung von Messwerten erst bei Änderungen außerhalb der Fehlertoleranz bleibt interessant. Sie zeigt die wesentlichen Daten ohne Schwankungen durch Messungenauigkeiten und braucht bei 2 minütiger Abtastrate bisher nur ca. 1/8 gespeicherte Messwerte im Vergleich zur stündlichen Abtastrate. Dies ergibt eine hohe Informationsdichte. Diese Persistierstrategie ist vielleicht mit InfluxDB nicht gut kompatibel. Vielleicht ist in CQs die Verwendung des zuletzt gespeicherten Wertes bei fehlenden Werten innerhalb der zugeordneten Zeitdifferenz dafür geeignet. Dazu kenne ich InfluxDB noch nicht gut genug.
Vielleicht läuft ein InfluxDB System auf einem Raspberry Pi 4 mit 8 GB Arbeitsspeicher stabiler. Das werde ich demnächst einmal testen. Es ist anscheinend nach wie vor am sichersten, wenn man über viele Ressourcen verfügt. 
2021-08-29
Ein Raspberry Pi 4 mit 8 GB RAM und einer SSD ist nun meine smart home Zentrale. Bisher läuft darauf Mosquitto, Node-RED, InfluxDB und inzwischen auch Grafana ohne Probleme, soweit ich das sehen kann.
Auf der Kommandozeile habe ich per "influx" 8 Retention Policies eingerichtet. "autogen" ist nicht mehr die default Richtlinie, derzeit verwende ich sie auch nicht mehr.
Per 7 Continuous Queries lasse ich sukzessive die Messreihen bis zu 2 Jahre und Mittelwertbildung alle 4 Tage verdichten. Jeweils verdichtet eine Abfrage die Datenpunkte per Mittelwertbildung aus der vorherigen mit der passenden Aufbewahrungsrichtlinie. Bisher funktioniert es so, wie geplant. Ich bin zuversichtlich.
Das Sichern der Datenbank kann ich bisher ausschließlich lokal durchführen. Ich werde bei Muße mal rsync genauer betrachten.
Grafana bietet sehr komfortable Möglichkeiten, die Grafiken aus meiner InfluxDB Datenbank zu lesen. Mit Kenntnisse der InfluxQL gelingt mir das auch fehlerfrei. Die Klick- und Auswahltechnik dazu setze ich nur vorbereitend ein und passe die QL-Anweisung nach meinen Bedürfnissen an.
Nach wie vor gefallen mir die Node-RED Grafiken sehr gut. Allerdings muss ich dafür die Datenbank-Ergebnisse per JavaScript passend transferieren. Die von mir erstellte entsprechende Funktion ist vielseitig einsetzbar und so relativ leicht bei Bedarf anzupassen. Es sind halt Kenntnisse im JSON-Format erforderlich. Bisher lasse ich zu jeder Grafik eine Datenbankabfrage durchführen. Gelegentlich will ich versuchen, für beide Messwerte (Temperatur, Wasservorrat) je qualifiziertem measurement name, bspw. Monate_1.Nutzwerte, nur eine Abfrage einzusetzen und die eintreffenden Werte (msg.payload...) auf beide Grafiken zu verteilen.
Die Grafana-Grafiken werden erfreulicherweise angezeigt, ohne dass sich der Browser dabei wegen des Cachen "verschluckt". Dies geschieht zuweilen leider bei den Node-RED Grafiken. Ich werde weiterhin beide pflegen.
2021-09-04
Der InfluxDB Datenbankserver läuft auf dem neuen Raspberry 4 mit 8 GB RAM bisher zuverlässig. Die Zeitfunktionsgrafiken per Grafana haben bei meiner Frau volle Akzeptanz. 
Zwischenzeitlich musste ich feststellen, dass zwar wenig häufig aber hin und wieder die Nutzwerte nicht übertragen werden. Das ist für die Speicherung und deren grafischer Darstellung unerheblich. Allerdings ist es für die automatische Wasserzufuhr nicht akzeptabel. Ursache dieses kleinen Mangels ist die in Tasmota verwendete MQTT-Bibliothek "pubsub client", in welcher keine QoS (Quality of Service) Stufen implementiert sind. QoS 2 wäre für die Wasserzufuhrsteuerung angemessen/erforderlich. Die MQTT Nachricht hierfür "retained" zu machen, ist kontraproduktiv, weil sich damit auch ungewollte "Phantom"-Schaltvorgänge ereignen.
Ich nehme verschiedene Workarounds bzgl. des verlässlichen Übertragens der MQTT Steuerungsnachricht in den Fokus.
- HTTP Nachricht statt MQTT
- mehrfaches Senden der MQTT Nachricht
- Der Empfänger sendet die MQTT Nachricht zum löschen der empfangenen retained Nachricht (Topic mit leerer Payload).
Da die Messwerte leicht per Grafiken auch aus der Ferne abrufbar sind und die Wasserzufuhr manuell per MQTT Dash gesteuert werden kann, ist dieses Vorhaben nicht dringlich.
2021-09-13
Die Zusammenarbeit von Zisternenmesssystem, Node-RED, InfluxDB und Grafana reift. Irgendwann werde ich mir noch Telegraf von influxdata ansehen.
Nach vielen Experimenten mit Grafana habe ich endlich die Möglichkeit gefunden, mehrere Grafiken mit jeweils eigener Zeitachse in einem Dashboard unterzubringen. Auch das Auf- und Zuklappen mit "Rows" funktioniert bestens. Nun steht eine Webseite für den Zisternen-Wasservorrat und mehr mit Grafiken in verschiedenen Zeitabschnitten von 24 Stunden bis derzeit 1/2 Jahr zur Verfügung. Dies bietet differenzierte Betrachtungsvarianten und einen guten Überblick. Jede Grafik wird durch eine Legende in Tabellenform ergänzt, in welcher aussagekräftige Zahlenwerte aufgeführt sind.
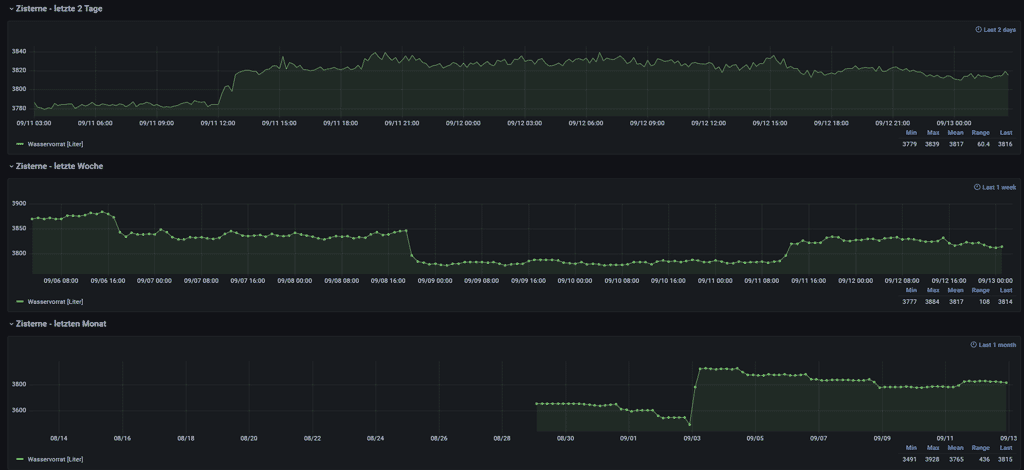
2021-09-28
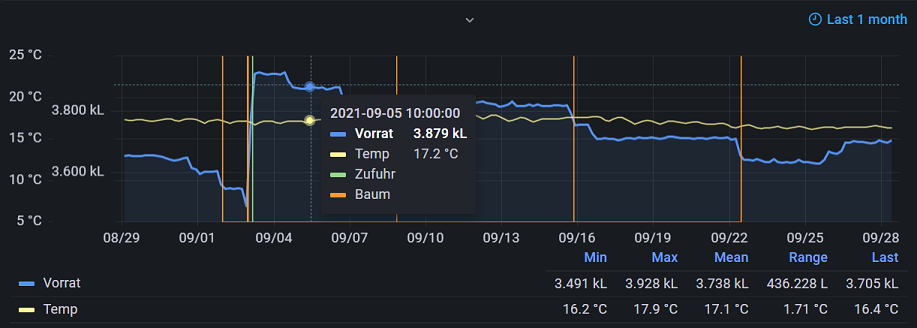
Die smart home Zentrale, ein Raspberry Pi 4 mit 8GB Arbeitsspeicher, läuft seit einem Monat 24/7 ohne Ausfall. Die Messwerte werden zuverlässig u.a. in der InfluxDB Datenbank gespeichert. Die Grafana Grafiken werden zuverlässig zusammengestellt.
Auch das ESP32 Messsystem arbeitet seit einem Monat ohne Unterbrechung und liefert im Rahmen von MQTT QoS Stufe 0 fast lückenlos die Messwerte. Für diesen Einsatzzweck stufe ich dies als hohe Zuverlässigkeit ein.
Die Messwertschwankungen/Messungenauigkeiten haben ein wenig zugenommen. Bei einem Wasservorrat von 3700 Liter habe ich eine Toleranz von etwa ±25 Liter abgelesen. In dieser Konstellation beträgt die relative Messtoleranz ca. ±0,7%. Möglicherweise hängt diese Zunahme mit Wasserdampfkondensat am Ultraschallaktor/-sensor zusammen. Ich werde die Messtoleranz weiterhin beobachten, insbesondere bei erheblich kleineren und erheblich größeren Werten des Wasservorrats.
Gelegentlich will ich das zwischenzeitliche Deaktivieren des Tasmota-Treibers erproben, um den Ultraschallsensor langsamer altern zu lassen.
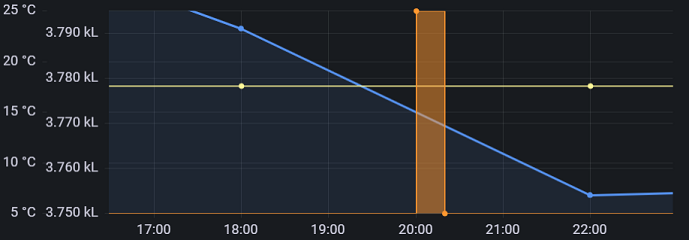
Inzwischen habe ich die Grafiken für unsere Zwecke weiter ausgestaltet und dabei festgestellt, wie vielseitig Grafana Grafiken konfiguriert werden können. Die folgende Abbildung zeigt verschiedene Werte in einer Grafik. Die senkrechten Striche sind tatsächlich Ein- und Ausschaltvorgänge, die zeitlich relativ dicht aufeinander folgen. Die orangen "Striche" zeigen jeweils eine per MQTT gesteuerte und gespeicherte Bewässerung unseres noch jungen Baumes, bspw. aus der Ferne.
Per Mauszeiger kann ein kleiner Zeitausschnitt gewählt werden. Darin ist ein solcher "Strich" als Schaltänderungen erkennbar und die Schaltzeitpunkte (ein/aus) ablesbar. Die unten abgebildete Bewässerung dauerte 20 Minuten. Diese seltener auftretenden Schaltereignisse lasse ich dauerhaft ohne Komprimierung speichern. Weil die älteren Wasservorratswerte per Mittelwerte gebildet werden, scheint die Abnahme des Vorrats vor der Wasserentnahme zu beginnen und zeitlich versetzt zu enden, was nicht der Realität entspricht. Dies lässt sich jedoch leicht geeignet interpretieren. Solche Feinheiten dürften in üblichen Anwendungen kaum genutzt werden. Sie können bei Bedarf dazu dienen, das veränderte Wasservolumen abzulesen und ggf. die Dauer oder den Durchfluss per Stellventil anzupassen. Dies lässt sich auch per MQTT Dash ohne Grafik erfassen, allerdings nicht zurückliegend.